지난해 회사를 옮기고 난 후 필요에 의해 스터디도 많이 하고 논문도 원없이 보고 있는거 같다.
처음엔 도대체 이게 뭔가 싶었는데, 논문들을 계속 보다보니 왠지 이젠 스크래치로 구현도 가능할 것 같아서 실현을 해보기 위해 지난 2월 데스크탑을 업그레이드 했다.
그 결과물들은 요기:
지난해 회사를 옮기고 난 후 필요에 의해 스터디도 많이 하고 논문도 원없이 보고 있는거 같다.
처음엔 도대체 이게 뭔가 싶었는데, 논문들을 계속 보다보니 왠지 이젠 스크래치로 구현도 가능할 것 같아서 실현을 해보기 위해 지난 2월 데스크탑을 업그레이드 했다.
그 결과물들은 요기:
최근 업무 관련해서 XLA를 알게 되었는데, 재밌는 프로젝트인데 반해 관련된 자료를 찾는게 쉽지 않길래 한번 소개를 해보면 좋을 것 같다는 생각이 들었습니다.
![]()
우선 XLA (Accelerated Linear Algebra)는 Tensorflow의 서브 프로젝트로 그래프 연산의 최적화 / 바이너리 사이즈의 최소화 등을 목적으로 하는 컴파일러입니다.
재밌어보이길래 python으로 간단한 슬랙봇을 만들어볼까 하고 알아봤더니 slackbot이란 모듈을 사용하면 슬랙봇을 쉽게 만들 수 있을것 같아서 슬랙봇을 만들어봤다.
그런데 파이썬 프로세스는 멀쩡하게 살아있지만 하루 정도가 지나면 봇이 disconnected 상태로 바뀌는 문제가 지속적으로 발생하는 문제가 있었다. 관련해서 예제 코드들을 찾아봐도 별다른 부분이 없길래 며칠 동안 디버깅을 하면서 문제를 해결해봤다.
우선 인터넷에 떠도는 slacker 기반 echo 봇의 기본 골격은 아래와 같았는데…
최근 python을 익히고, 많은 일들을 python으로 처리하기 시작했는데 미디어에서 프레임을 추출하는 모듈 중에 깔끔한 모듈을 못찾겠어서 직접 모듈을 하나 만들었다.
Continue reading pydemux: simple ffmpeg wrapper
얼마전 네이버에서 고정폭 서체인 ‘나눔고딕_코딩’ 서체를 OFL(Open Font License)로 공개하였고, gd를 이용해서 뽑은 12pt 샘플은 다음과 같습니다.
gd의 문제로 인하여 영문과 한글의 폭이 동일하게 출력되었는데, 맥이나 윈도우, 리눅스(약간의 설정 필요) 등에서는 영문과 한글의 폭이 2:1 이다보니 서체 이름에서와 동일하게 코딩용으로 사용하기에 딱이겠네요.
* http://dev.naver.com/projects/nanumfont
덧: 서체 이름에 사용된 언더바(‘_’) 때문에 맥에서 약간의 문제가 있었는데, 서체가 업데이트 되면서 이름이 ‘나눔고딕코딩’으로 바뀌었고, 맥에서도 문제 없이 사용할 수 있게 되었습니다.
내 눈엔 순천향체가 젤 이뻐보인다. 참고로 프리뷰에서 ‘아햏햏, 똠방각하’가 제대로 보이질 않는다면 한글 2350자만을 지원하는 서체임.
| 패키지 | 서체이름 | 스타일 | 구분 | 프리뷰 |
|---|---|---|---|---|
| 나눔글꼴 | 나눔고딕 | Regular | 한글 11,172자 |  |
| Bold | 한글 11,172자 |  |
||
| 나눔명조 | Regular | 한글 11,172자 |  |
|
| Bold | 한글 11,172자 |  |
||
| 나눔고딕코딩 | 나눔고딕코딩 | Regular | 한글 11,172자 |  |
| Bold | 한글 11,172자 |  |
||
| 다음체 | 다음 | Regular | 한글 2,350자 |  |
| SemiBold | 한글 2,350자 |  |
||
| 렉시굴림 | 렉시굴림 | Regular | 한글 2,350자 |  |
| 서울 서체 | 서울 남산체 | Light | 한글 11,172자 |  |
| Regular | 한글 11,172자 |  |
||
| Bold | 한글 11,172자 |  |
||
| ExtraBold | 한글 11,172자 |  |
||
| 서울 한강체 | Light | 한글 11,172자 |  |
|
| Regular | 한글 11,172자 |  |
||
| 순천향체 | 순천향체 | Regular | 한글 2,350자 |  |
| 아리따체 | 아리따 | Light | 한글 11,172자 |  |
| Regular | 한글 11,172자 |  |
||
| SemiBold | 한글 11,172자 |  |
||
| Bold | 한글 11,172자 |  |
||
| 은글꼴 | 은돋움 | Regular | 한글 11,172자 |  |
| Bold | 한글 11,172자 |  |
||
| 은그래픽 | Regular | 한글 11,172자 |  |
|
| Bold | 한글 11,172자 |  |
||
| 은궁서 | Regular | 한글 11,172자 |  |
|
| 은바탕 | Regular | 한글 11,172자 |  |
|
| Bold | 한글 11,172자 |  |
||
| 은필기 | Regular | 한글 11,172자 |  |
|
| Bold | 한글 11,172자 |  |
||
| 한겨레결체 | 한겨레결체 | Regular | 한글 11,172자 |  |
| ttf-alee | 은진 | Regular | 한글 11,172자 |  |
| 은진낙서 | Regular | 한글 11,172자 |  |
|
| 구슬 | Regular | 한글 전용 |  |
|
| 반달 | Regular | 한글 11,172자 |  |
|
| 방울 | Regular | 한글 11,172자 |  |
|
| 네이버 사전체 | 네이버 사전체 | Regular | 한글 11,172자 |  |
| 연체체 | 연세 제목체 | Regular | 한글 2,350자 |  |
| 연세 소제목체 | Regular | 한글 2,350자 |  |
|
| 연세 로고체 | Regular | 영문, 숫자 |  |
|
| 조선일보 명조체 | 조선일보 명조체 | Regular | 한글 11,172자 |  |
| 문화부 글꼴 | Regular | 한글 2,350자 | ||
| 백묵 글꼴 | Regular | 한글 11,172자 |
위 결과는 cairo+freetype을 이용해서 렌더링한 결과입니다. 사용된 소스는 아래 URL에서 확인하실 수 있습니다.
* http://mytears.org/tmp/cairo/text.c
팩스에서 처럼 이미지를 흑/백 으로만 표현할 수 있는 경우에도 어느 정도의 명암을 표현하기 위한 방법으로 아래와 같은 오리지널 이미지가 있을 때…

한 픽셀 값은 0~255 사이의 값을 가진다고 하고, 128 이상의 값은 하얀 색으로, 128 미만 값은 검은 색으로 표현하면 결과는 다음과 같다.

보다시피 디테일은 거의 사라져버리기 때문에 이런 것을 피하기 위해 디더링이란 기법을 사용하곤 한다. 수식으로 이를 표현해보자면 다음과 같고…
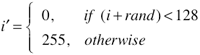
말로 설명하자면 랜덤 값을 더해준 뒤 128 을 기준으로 Thresholding 을 한다! 정도로 표현이 가능할 듯… 이론적으론 매우 간단하지만 효과는 확실하다. -16~16 의 랜덤 값을 이용하여 dithering 한 결과는 다음과 같다.
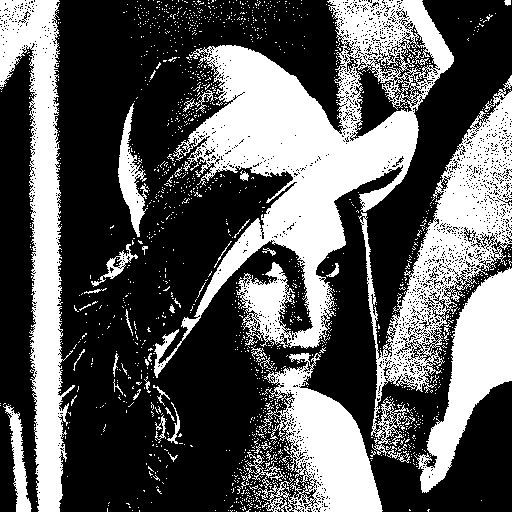
-32~32 사이의 랜덤 값을 이용할 경우는…
확실히 좀 디테일이 조금 생겨나는 것을 확인할 수가 있다. 장비들이 좋아지면서 이런 식의 트릭들에 대한 연구는 사라져가는 것 같다. -_ㅠ
위 테스트에 사용한 코드:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
#include <stdio.h> #include <time.h> #include <stdlib.h> int main( int argc, char** argv ){ int i, j; unsigned char* src; unsigned char* dst; FILE* in; FILE* out; src = (unsigned char*)malloc(sizeof(unsigned char)*512*512); dst = (unsigned char*)malloc(sizeof(unsigned char)*512*512); srand(time(NULL)); in = fopen("lena512.raw", "rb" ); fread( src, sizeof(unsigned char), 512*512, in ); fclose(in); for( j = 0 ; j < 512 ; j++ ){ for( i = 0 ; i < 512 ; i++ ){ if( src[j*512+i] > 128 ) dst[j*512+i] = 255; else dst[j*512+i] = 0; } } out = fopen("lena512_thres.raw", "wb" ); fwrite( dst, sizeof(unsigned char), 512*512, out ); fclose(out); for( j = 0 ; j < 512 ; j++ ){ for( i = 0 ; i < 512 ; i++ ){ if( (src[j*512+i] + rand()%32 - 32) > 128 ) dst[j*512+i] = 255; else dst[j*512+i] = 0; } } out = fopen("lena512_dither_32.raw", "wb" ); fwrite( dst, sizeof(unsigned char), 512*512, out ); fclose(out); return 0; } |
kldp 를 눈팅하다가 오늘 재밌는 문서를 읽게 되었습니다. 2001년도에 AMD 에서 나온 문서였는데, 그 내용이 상당히 흥미로워서 몇 가지 내용을 옮겨볼까 합니다.
메모리에서 연속된 값들을 다른 곳으로 복사하기 위해 사용할 수 있는 가장 간단한 어셈블리 코드는 다음과 같습니다.
|
1 2 3 4 5 |
mov esi, [src] // source array mov edi, [dst] // destination array mov ecx, [len] // number of QWORDS (8 bytes) shl ecx, 3 // convert to byte count rep movsb |
rep movsb 명령은 repeat move single byte (바이트 단위로 값들을 반복해서 옮긴다.)라는 의미를 가집니다. esi 가 가리키는 곳에 있는 값을 edi 로 ecx 에 있는 개수 만큼 복사하게 됩니다. 이렇게 할 경우 일초에 약 620MB 를 복사할 수 있다고 하네요.
이 코드를 byte 단위가 아니라 4 byte 단위로 반복해서 복사를 하도록 하면 어떻게 될까요? 우선 코드는 다음과 같이 변하겠네요.
|
1 2 3 4 5 |
mov esi, [src] // source array mov edi, [dst] // destination array mov ecx, [len] // number of QWORDS (8 bytes) shl ecx, 1 // convert to DWORD count rep movsd |
shl 인스트럭션은 두개의 오퍼랜드를 가지며 (shl operand1 operand2) operand1 에 있는 값을 operand2 에 있는 값만큼 왼쪽으로 shift 를 시키게 됩니다. movsd 는 mov single dword[1] 라고 보시면 됩니다.
결과적으로 이렇게 코드를 수정함으로 인해 1초에 640MB 를 복사할 수 있게 됩니다. 3% 정도 성능 향상이 생기네요.
그런데 최근에 나온 프로세서들에서는 rep 같은 복잡한 인스트럭션을 내부적으로 RISC 명령으로 바꿔서 실행하다 보니, 그리 효율적이지 못하답니다. 그러므로 rep 를 사용하지 말고 반복문을 사용해보도록 합시다.
|
1 2 3 4 5 6 7 8 9 10 11 |
mov esi, [src] // source array mov edi, [dst] // destination array mov ecx, [len] // number of QWORDS (8 bytes) shl ecx, 1 // convert to DWORD count copyloop: mov eax, dword ptr [esi] mov dword ptr [edi], eax add esi, 4 add edi, 4 dec ecx jnz copyloop |
코드가 뭔가 좀 길어졌죠? 위 코드를 c로 표현하면 아래와 같습니다.
|
1 2 3 4 5 |
int* src = esi; int* dst = edi; int i; for( i = len ; i != 0 ; i-- ){ dst++ = src++; |
c로 표현하니 어디서 많이 쓰던 코드죠? 쨌든! 이렇게 하니 1초에 650MB 를 복사할수 있었고 결과적으로 1.5% 정도 성능이 향상되었답니다.
그럼 여기다가 Loop 코드를 최적화 하는 기법인 Loop Unrolling 을 적용해봅시다. [2]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
mov esi, [src] // source array mov edi, [dst] // destination array mov ecx, [len] // number of QWORDS (8 bytes) shr ecx, 1 // convert to 16-byte size count // (assumes len / 16 is an integer) copyloop: mov eax, dword ptr [esi] mov dword ptr [edi], eax mov ebx, dword ptr [esi+4] mov dword ptr [edi+4], ebx mov eax, dword ptr [esi+8] mov dword ptr [edi+8], eax mov ebx, dword ptr [esi+12] mov dword ptr [edi+12], ebx add esi, 16 add edi, 16 dec ecx jnz copyloop |
자 룹을 펼쳤더니 1초에 640MB 를 복사하였고, 결과적으로 1.5% 만큼 성능이 떨어졌습니다. 하지만 다행히도 Loop Unrolling 을 적용하고 나니 최적화를 할 여지가 많아졌네요.
캐쉬를 좀 더 잘 활용할 수 있도록 코드 순서를 바꿔봅시다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
mov esi, [src] // source array mov edi, [dst] // destination array mov ecx, [len] // number of QWORDS (8 bytes) shr ecx, 1 // convert to 16-byte size count copyloop: mov eax, dword ptr [esi] mov ebx, dword ptr [esi+4] mov dword ptr [edi], eax mov dword ptr [edi+4], ebx mov eax, dword ptr [esi+8] mov ebx, dword ptr [esi+12] mov dword ptr [edi+8], eax mov dword ptr [edi+12], ebx add esi, 16 add edi, 16 dec ecx jnz copyloop |
이젠 1초에 660MB 를 복사할 수 있게 되었고, 3% 만큼 성능 향상이 일어났습니다.
여기서 끝이 아닙니다. 첨에 movsb 대신 movd 를 사용해서 1byte씩이 아닌 4byte 씩 복사를 하는 방법을 통해 최적화를 진행했었는데요, MMX 를 사용할 경우 movq 등의 인스트럭션을 이용해서 한 번에 8byte 씩을 복사하는게 가능해집니다. 또한 mm0~7 이라는 특수한 레지스터를 활용할 수 있으니 8*8 = 64 즉 한번에 64byte 씩을 복사해봅시다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
mov esi, [src] // source array mov edi, [dst] // destination array mov ecx, [len] // number of QWORDS (8 bytes) lea esi, [esi+ecx*8] // end of source lea edi, [edi+ecx*8] // end of destination neg ecx // use a negative offset copyloop: movq mm0, qword ptr [esi+ecx*8] movq mm1, qword ptr [esi+ecx*8+8] movq mm2, qword ptr [esi+ecx*8+16] movq mm3, qword ptr [esi+ecx*8+24] movq mm4, qword ptr [esi+ecx*8+32] movq mm5, qword ptr [esi+ecx*8+40] movq mm6, qword ptr [esi+ecx*8+48] movq mm7, qword ptr [esi+ecx*8+56] movq qword ptr [edi+ecx*8], mm0 movq qword ptr [edi+ecx*8+8], mm1 movq qword ptr [edi+ecx*8+16], mm2 movq qword ptr [edi+ecx*8+24], mm3 movq qword ptr [edi+ecx*8+32], mm4 movq qword ptr [edi+ecx*8+40], mm5 movq qword ptr [edi+ecx*8+48], mm6 movq qword ptr [edi+ecx*8+56], mm7 add ecx, 8 jnz copyloop emms // empty the MMX state |
MMX 용 레지스터들인 mm0~7 은 FPU stack 의 일부를 활용하게 되므로, 이 레지스터 값을 바꿔주게 될 경우 FPU 와 관련해서 문제를 일으킬 수 있습니다. EMMX 는 이를 방지하기 위해 사용해야 하는 인스트럭션이 되겠습니다. 하여튼 이렇게 바꾸니 1초에 705MB 를 복사할 수 있게 되었고, 7% 만큼 성능이 향상되었습니다.
이젠 movntq 라는 인스트럭션을 통해 cache 를 우회해서 writing 을 진행해봅시다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
mov esi, [src] // source array mov edi, [dst] // destination array mov ecx, [len] // number of QWORDS (8 bytes) lea esi, [esi+ecx*8] lea edi, [edi+ecx*8] neg ecx copyloop: movq mm0, qword ptr [esi+ecx*8] movq mm1, qword ptr [esi+ecx*8+8] movq mm2, qword ptr [esi+ecx*8+16] movq mm3, qword ptr [esi+ecx*8+24] movq mm4, qword ptr [esi+ecx*8+32] movq mm5, qword ptr [esi+ecx*8+40] movq mm6, qword ptr [esi+ecx*8+48] movq mm7, qword ptr [esi+ecx*8+56] movntq qword ptr [edi+ecx*8], mm0 movntq qword ptr [edi+ecx*8+8], mm1 movntq qword ptr [edi+ecx*8+16], mm2 movntq qword ptr [edi+ecx*8+24], mm3 movntq qword ptr [edi+ecx*8+32], mm4 movntq qword ptr [edi+ecx*8+40], mm5 movntq qword ptr [edi+ecx*8+48], mm6 movntq qword ptr [edi+ecx*8+56], mm7 add ecx, 8 jnz copyloop sfence emms |
movntq 를 활용한 다음에는 write buffer 를 비워주기 위해 sfence 를 사용해야 한다는군요. write 부분이 movq 에서 movntq 로 바뀌었고 emms 앞에 sfence 가 들어간 것을 제외하면 코드는 동일합니다. 하지만 성능 향상은 60% 로 굉장하네요. 1초에 1130MB 를 복사할 수 있었다고 합니다.
이젠 prefetch 도 활용해봅시다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
mov esi, [src] // source array mov edi, [dst] // destination array mov ecx, [len] // number of QWORDS (8 bytes) lea esi, [esi+ecx*8] lea edi, [edi+ecx*8] neg ecx copyloop: prefetchnta [esi+ecx*8 + 512] // fetch ahead by 512 bytes movq mm0, qword ptr [esi+ecx*8] movq mm1, qword ptr [esi+ecx*8+8] movq mm2, qword ptr [esi+ecx*8+16] movq mm3, qword ptr [esi+ecx*8+24] movq mm4, qword ptr [esi+ecx*8+32] movq mm5, qword ptr [esi+ecx*8+40] movq mm6, qword ptr [esi+ecx*8+48] movq mm7, qword ptr [esi+ecx*8+56] movntq qword ptr [edi+ecx*8], mm0 movntq qword ptr [edi+ecx*8+8], mm1 movntq qword ptr [edi+ecx*8+16], mm2 movntq qword ptr [edi+ecx*8+24], mm3 movntq qword ptr [edi+ecx*8+32], mm4 movntq qword ptr [edi+ecx*8+40], mm5 movntq qword ptr [edi+ecx*8+48], mm6 movntq qword ptr [edi+ecx*8+56], mm7 add ecx, 8 jnz copyloop sfence emms |
위 코드에는 현재 복사할 차례의 512 바이트를 미리 읽어두라는 의미의 prefetchnta 인스트럭션이 추가되었습니다. 한 번에 복사하는건 64Byte 인데 왜 512Byte 를 읽으라고 했는지 살짝 의문이네요. 제 생각에는 문서를 작성하신 분이 버그를 낸거라고 생각합니다.
하여튼 이젠 1초에 1240MB 를 복사할 수 있게 되었고, 10% 만큼 더 성능 향상이 생겼네요.
지금까지의 방법만으로도 꽤 많은 성능 향상이 있었지만, 한 번에 한 캐쉬 라인[3]만을 활용하고 있습니다. 하지만 실제 CPU 에는 훨씬 많은 캐쉬 라인이 존재하므로 이를 더 잘 활용할 수 있도록 코드를 수정해보겠습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
#define CACHEBLOCK 400h // number of QWORDs in a chunk mov esi, [src] // source array mov edi, [dst] // destination array mov ecx, [len] // total number of QWORDS (8 bytes) // (assumes len / CACHEBLOCK = integer) lea esi, [esi+ecx*8] lea edi, [edi+ecx*8] neg ecx mainloop: mov eax, CACHEBLOCK / 16 // note: prefetch loop is unrolled 2X add ecx, CACHEBLOCK // move up to end of block prefetchloop: mov ebx, [esi+ecx*8-64] // read one address in this cache line... mov ebx, [esi+ecx*8-128] // ... and one in the previous line sub ecx, 16 // 16 QWORDS = 2 64-byte cache lines dec eax jnz prefetchloop mov eax, CACHEBLOCK / 8 writeloop: movq mm0, qword ptr [esi+ecx*8] movq mm1, qword ptr [esi+ecx*8+8] movq mm2, qword ptr [esi+ecx*8+16] movq mm3, qword ptr [esi+ecx*8+24] movq mm4, qword ptr [esi+ecx*8+32] movq mm5, qword ptr [esi+ecx*8+40] movq mm6, qword ptr [esi+ecx*8+48] movq mm7, qword ptr [esi+ecx*8+56] movntq qword ptr [edi+ecx*8], mm0 movntq qword ptr [edi+ecx*8+8], mm1 movntq qword ptr [edi+ecx*8+16], mm2 movntq qword ptr [edi+ecx*8+24], mm3 movntq qword ptr [edi+ecx*8+32], mm4 movntq qword ptr [edi+ecx*8+40], mm5 movntq qword ptr [edi+ecx*8+48], mm6 movntq qword ptr [edi+ecx*8+56], mm7 add ecx, 8 dec eax jnz writeloop or ecx, ecx // if( ecx != 0 ) jnz mainloop // goto mainloop sfence |
여기서는 cache 가 1024 개의 cache line 을 가지고 있다고 가정했네요. (16진수인 400h 는 10진수로 바꿀 경어 1024 가 됩니다.) 미리 캐쉬 사이즈만큼 prefetch 명령들을 내려놓은 뒤 값들을 복사하게 될 때 쯤이면 이미 값들이 캐쉬에 올라와있게 되니 딜레이를 줄일 수 있게 되겠습니다.
효과가 있을까 싶지만, 실제 1초에 1976MB 를 복사할 수 있었고, 59% 의 성능향상이 추가로 발생했습니다. 초기 코드에 비하면 300% 의 성능 향상이라네요. 신기하죠. 😉
전 상당히 흥미롭게 읽었었는데, (비슷한 걸 해본 경험도 있고 해서) 재밌었는지 모르겠네요. sfence 나 movqnta, prefetchnta 같은 캐쉬와 관련된 명령들은 정확히 무슨 용도인지 이해하지 못하고 있었는데 이 문서를 통해 이해할 수 있었던 것 같네요. 관심이 있으신 분은 아래 문서를 읽어보시면 되겠습니다. FPU 관련된 최적화도 다루고 있는데, 관심이 없어서 그 부분은 옮기질 않았습니다. 그럼 다들 즐거운 주말 보내시길 😉
[1] x86 호환 아키텍쳐에서는 사이즈를 byte, word, dword, qword, dqword 식으로 표현합니다. 이는 각각 1, 2, 4, 8, 16 바이트를 의미하며, word 가 2바이트이고 나머지의 앞에 붙은 알파벳들은 각각 double(*2), quad(*4), double quad(*8)를 나타내는 것이죠.
[2] Loop Unrolling 은 Loop 을 펼쳐서 파이프라인의 덕을 더 많이 볼 수 있도록 코드를 수정하는 방법입니다. 예를 들어
|
1 2 |
for ( i = 0 ; i < 16 ; i++ ) dst[i] = src[i]; |
|
1 2 3 4 5 6 |
for ( i = 0 ; i < 16 ; i+=4 ){ dst[i] = src[i]; dst[i+1] = src[i+1]; dst[i+2] = src[i+2]; dst[i+3] = src[i+3]; } |
왠지 모르게 점점 마이너 한 것들만 사용하게 되네요. postfix 나 exim 을 사용해보니 여러가지 장점이 눈에 보이는데 막상 how to 문서같은게 그리 잘 나와있질 않다보니 사람들이 사용하기를 꺼리는 것 같아 처음으로 howto 문서를 하나 작성해려 합니다.
이 문서는 젠투에서 exim 을 사용하는 방법을 기준으로 설명하고 있습니다.
Mail Transfer Agent 로는 exim, 스팸 필터로는 bogofilter, 바이러스 필터는 clamav, pop3/imap server 로는 dovecot 을 사용하기로 하겠습니다. dovecot 이나 exim 이나 기본 적으로 실행하는 프로세스들이 많지 않기 때문에 프로세스 리스트를 확인할 때 깔끔해서 좋더군요.
저 같은 경우는 대강 다음과 같은 USE 플래그를 이용해서 설치를 진행했습니다.
|
1 2 3 4 5 6 7 8 9 |
emerge -pv exim bogofilter clamav dovecot procmail These are the packages that would be merged, in order: Calculating dependencies... done! [ebuild R ] mail-mta/exim-4.69 USE="domainkeys dovecot-sasl exiscan exiscan-acl gnutls ipv6 pam perl sasl spf sqlite srs ssl syslog tcpd -X -dnsdb -ldap -lmtp -mailwrapper -mbox -mbx -mysql -nis -postgres -radius" 0 kB [ebuild R ] mail-filter/bogofilter-1.1.6 USE="berkdb sqlite -gsl" 0 kB [ebuild R ] app-antivirus/clamav-0.92.1-r1 USE="bzip2 crypt milter nls -mailwrapper (-selinux)" 14,927 kB [ebuild R ] net-mail/dovecot-1.0.13-r1 USE="ipv6 pam pop3d ssl -debug -doc -kerberos -ldap -managesieve -mbox -mysql -postgres -sieve -suid -vpopmail" 0 kB [ebuild R ] mail-filter/procmail-3.22-r7 USE="-mbox (-selinux)" 222 kB Total: 5 packages (5 reinstalls), Size of downloads: 15,149 kB |
domainkeys 는 야후나 구글에서 사용하고 있는 domain key 를 제대로 검증하기 위한 USE 플래그가 되겠구요, dovecot-sasl 은 smtp 인증에 dovecot 을 이용하기 위한 플래그입니다.
spf, srs, domainkey 같은 플래그는 해당 기능을 사용하지 않겠다면 빼주셔도 무방합니다. CentOS 등에서는 dovecot-sasl 도 기본으로 지원이 안되더라구요. 하튼 관련해서 자세한 건 뒤에서 설명하도록 하겠습니다.
살펴보니 별로 특이한 플래그를 사용하지는 않네요. -_;; 젠투 유져라면 다들 아시겠지만 실제 설치는 위의 예제에서 -pv 를 제거하고 실행시키시면 됩니다.
설치가 무사히 끝났다면 가상호스트를 설정해봅시다. 젠투에서는 기본으로 설정파일을 만들어주지 않습니다. 그렇기 때문에 우선 /etc/exim/exim.conf.dist 를 복사해서 exim.conf 를 만들어줍니다.
# cp /etc/exim/exim.conf.dist /etc/exim/exim.conf
그런 다음 자신이 좋아하는 편집기를 이용해서 exim.conf 파일을 열고, 아래와 같은 부분을 찾아서 자신의 환경에 맞게 수정을 한 뒤
|
1 2 3 4 |
primary_hostname = unfix.net domainlist local_domains = @ : localhost : dsearch;/etc/exim/virtual domainlist relay_to_domains = hostlist relay_from_hosts = 127.0.0.1 |
router 부분에서 system_alias 바로 아래에 다음 코드를 추가해줍니다.
|
1 2 3 4 5 6 7 8 9 |
virtual: driver = redirect allow_fail allow_defer domains = dsearch;/etc/exim/virtual data = ${expand:${lookup{$local_part}lsearch*@{/etc/exim/virtual/$domain}}} retry_use_local_part file_transport = address_file pipe_transport = address_pipe |
주 도메인이 있는 경우 localhost 대신 unfix.net 같은 도메인을 사용해도 무방합니다. 만약 위의 예제에서 localhost 대신 unfix.net 을 설정해주면 로컬에 있는 모든 계정은 id@unfix.net 형태의 메일계정으로 사용이 가능해집니다. 주 도메인이 여러개라면 @ : localhost : mydomain1 : mydomain2 식으로 콜론(:) 을 이용해서 여러 개를 모두 적어주면 되겠습니다.
이젠 가상 호스트를 설정해봅시다. 만약 test.com 과 test.net 을 위한 가상호스트를 설정하려 한다면 다음과 같이 하면 됩니다.
|
1 2 3 |
# mkdir /etc/exim/virtual # vi /etc/exim/virtual/test.com # vi /etc/exim/virtual/test.net |
위에서 dsearch; … 으로 설정해놓은 디렉토리 안에다가 호스트 이름을 이용해서 alias 파일을 만들어주면 되니까 간단하죠? 각 파일에 들어가는 내용은 다음과 같습니다.
# test.com
test: aqua@localhost
melong: test@gmail.com
# test.net
aqua: test@localhost
test.com 파일에 들어가 있는 test: aqua@localhost 는 test@test.com 으로 온 메일을 aqua@localhost 로 포워드를 시키라는 거에요. 워낙 간단하니 다른 것들은 따로 설명 안해도 될 것 같네요. 단 위에서 localhost 대신 myhost.net 을 사용했다면 aqua@myhost.net 처럼 설정해줘야 합니다.
여기까지 따라하셨다면 가상 호스트 설정은 끝! 가상 호스트 파일을 수정했을 때는 alias 를 수정했을 때와 달리 newalias 를 실행시키실 필요가 없습니다.
바이러스 필터로는 clamav 를 사용할 건데, USE 플래그로 exiscan 과 exiscan-acl 을 사용해서 설치했다면 clamd 와 연동하는건 아주 간단합니다.
exim.conf 에서 다음과 같은 줄을 찾아서 주석을 해제시키세요.
|
1 |
av_scanner = clamd:/var/run/clamav/clamd.sock |
끝! clamd.sock 위치는 배포판에 따라 다를 수 있습니다. 자세한건 /etc/clamd.conf 를 참조하세요.
Exim에는 기본으로 SPF와 관련된 코드가 있으므로 SPF를 사용하기 위해선 EXPERIMENTAL_SPF=yes 환경변수와 함께 exim을 빌드하면 됩니다.
설정은 global 섹션에서 acl_smtp_rcpt 로 등록되어 있는 것에 다음과 같은 설정을 넣어주면 됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
# Query the SPF information for the sender address domain, if any, # to see if the sending host is authorized to deliver its mail. # If not, reject the mail. # deny message = [SPF] $sender_host_address is not allowed to send mail \ from $sender_address_domain log_message = SPF check failed. spf = fail # Add a SPF-Received: header to the message warn message = $spf_received |
젠투에선 acl_smtp_rcpt가 acl_check_rcpt로 되어 있기 떄문에 acl_check_rcpt 부분에 위 설정을 추가해줬습니다.
만약 warn message = $spf_received 를 넣어주지 않으면 헤더에 SPF결과를 출력하지 않게됩니다. SPF헤더를 붙일 경우에는 SMTP Auth를 이용해서 메일을 보내는 경우에도 SPF헤더가 붙는 문제가 있습니다. 이를 피하기 위해 설정을 아래처럼 수정해주도록 합시다.
|
1 2 3 4 |
# Add a SPF-Received: header to the message warn message = $spf_received !authenticated = * |
SRS를 설정하기 위해 우선 global 섹션에 다음과 같은 내용을 추가해줍니다.
|
1 |
srs_config = somesecretkey |
여기서 somesecretkey는 본인이 원하는 임의의 문자열을 넣으면 되겠습니다. 그 후 다음과 같이 userforward에 ‘srs=forward’를 넣어주면 됩니다. 간단하죠.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
userforward: driver = redirect srs = forward check_local_user # local_part_suffix = +* : -* # local_part_suffix_optional file = $home/.forward # allow_filter no_verify no_expn check_ancestor file_transport = address_file pipe_transport = address_pipe reply_transport = address_reply |
스팸 필터로는 베이시안 룰 기반의 스팸 필터인 bogofilter를 사용해봅시다.
bogofilter를 MTA와 연동시키는 데는 procmail을 이용할 수도 있지만, procmail은 로컬 유져에 한해서만 사용이 가능하고, alias 나 .forward 를 사용하게 되는 경우에는 사용할 수 없으므로 exim의 transport와 router를 이용해보겠습니다.
우선 transport를 다음과 같이 설정합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
bogofilter: driver = pipe command = /usr/sbin/exim -oMr bogodone -bS use_bsmtp = true transport_filter = /usr/bin/bogofilter -d /etc/bogofilter/ -e -p log_output = true return_path_add = false temp_errors = * home_directory = "/tmp" current_directory = "/tmp" message_prefix = "" message_suffix = "" |
그리고 이 transport 를 이용하는 router를 만들어야 합니다. 참고로 router 는 순서에 민감하므로 삽입할 위치를 잘 선택해야 합니다. 저같은 경우는 system_alias 다음에다가 넣어두었습니다.
|
1 2 3 4 5 6 |
bogofilter: domains = +local_domains no_verify condition = ${if !eq {$received_protocol}{bogodone} {1}{0}} driver = accept transport = bogofilter |
여기까지만 하게 되면 bogofilter가 각각의 메일 헤더에 ‘이 메일이 스팸/햄이다.’ 라는 정보만을 넣어줄 뿐 스팸/햄을 다른 메일박스로 분류해주는 동작은 하질 않습니다.
그러므로 자동 분류를 위한 transport 와 router 를 또 추가해주도록 합니다.
transport 먼저…
|
1 2 3 4 5 6 7 |
spam_delivery: driver = appendfile directory = /home/$local_part/.maildir/.Spam maildir_format delivery_date_add envelope_to_add return_path_add |
이렇게 하면 자신의 홈 디렉토리의 .maildir 아래 .Spam 이란 디렉토리를 만들고, 그 디렉토리에 스팸 메일을 저장하게 됩니다.
IMAP 으로 접속하면 Spam 메일들을 확인할 수 있기 때문에 이렇게 했는데, POP3 만 사용하는 거라면 그냥 제목에 [Spam] prefix 를 붙이게 하는 것도 나쁘지 않을 것 같습니다.
그 다음엔 이 transport 를 이용하는 router를 설정해야하는데, 이 때도 위치를 잘 생각해야 합니다. 저같은 경우엔 bogofilter router 바로 아래에 위치시켜 놓았습니다..
|
1 2 3 4 5 |
removingspam: driver = accept check_local_user condition = ${if match {$h_X-Bogosity:} {Spam, tests=bogofilter} {1}{0}} transport = spam_delivery |
스팸 메일은 bogofilter 에 의해 X-Bogosity: Spam, test=bogofilter … 식의 헤더가 추가되기 때문에 이렇게 할 경우 스팸을 쉽게 분류해낼 수 있습니다.
우선 /etc/dovecot.conf 파일을 열어서 서비스할 프로토콜 리스트를 적어주세요. 그 다음에 plaintext 로 로그인할 수 있도록 설정해주고, pop3 나 imaps 를 위해 ssl 을 사용할거라고 명시해주고, 마지막으로 dovecot-sasl 을 사용할 수 있도록 auth-client 를 활성화시켜주세요.
이를 종합해보면 다음과 같은 설정파일이 만들어집니다. 볼드로 표시한 부분이 제가 수정한 부분이에요. 주석을 제거하고 보니 정말 간단하네요. -_-;
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
protocols = imap imaps pop3 pop3s listen = [::] disable_plaintext_auth = no ssl_disable = no ssl_cert_file = /etc/ssl/private/unfix.net.crt ssl_key_file = /etc/ssl/private/unfix.net.key mail_location = maildir:~/.maildir protocol imap { } protocol pop3 { pop3_uidl_format = %08Xu%08Xv } protocol lda { postmaster_address = postmaster@example.com } auth default { mechanisms = plain login passdb pam { args = "*" } userdb passwd { } user = root socket listen { client { path = /var/run/dovecot/auth-client mode = 0666 } } } |
그리고 /etc/pam.d 로 가서 smtp 파일이 있는지를 체크해보시고 만약 없다면 system-login 이나 pop 등을 복사해서 smtp 파일을 만들어주세요. 이것 때문에 어제 혈압이 올랐던걸 생각하면 …!!!
여기까지 설정하셨음 90% 는 끝난겁니다.
자 다시 exim.conf 로 돌아와서 smtp 인증을 설정해봅시다. exim.conf 에서 authenticators 파트를 찾아서 아래와 같은 내용을 추가해줍시다.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
plain: driver = dovecot public_name = PLAIN server_socket = /var/run/dovecot/auth-client server_set_id = $1 server_advertise_condition = 1 login: driver = dovecot public_name = LOGIN server_socket = /var/run/dovecot/auth-client server_set_id = $1 server_advertise_condition = 1 |
이걸로 설정은 끝! 다음엔 데몬들을 띄워서 제대로 되나 확인을 해보세요.
|
1 2 |
# /etc/init.d/dovecot start # /etc/init.d/exim start |
제가 이것저것 확인해본 건 아니라 정확하게 알려드릴 순 없지만 CentOS 에서는 spf, srs, dovecot-sasl, domainkeys 등을 사용할 수가 없습니다. 그렇기 때문에 dovecot-auth 대신 saslauthd 를 사용해야 해요. saslauthd 를 사용할 때의 authenticator 파트는 다음과 같습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
PLAIN: driver = plaintext public_name = PLAIN server_condition = ${if saslauthd{{$1}{$2}{smtp}}{1}{0}} server_set_id = $1 server_advertise_condition = true LOGIN: driver = plaintext public_name = LOGIN server_condition = ${if saslauthd{{$1}{$2}{smtp}}{1}{0}} server_set_id = $1 server_advertise_condition = true |
server_condition 을 다음처럼 하면 pam 만으로도 인증을 할 수 있습니다. 하지만 pam_auth 모듈에서 auth request를 보낸 사용자의 uid와 username을 가지고 확인하는 절차가 있기 때문에 exim을 root 권한으로 실행시키지 않으면 제대로 인증이 되지 않습니다.
|
1 |
server_condition = "${if pam{$2:$3}{1}{0}}" |
참고로 인증을 saslauthd 를 통해서 하려는 경우 saslauthd 가 실행 중에 있어야 합니다.

