최근 업무 관련해서 XLA를 알게 되었는데, 재밌는 프로젝트인데 반해 관련된 자료를 찾는게 쉽지 않길래 한번 소개를 해보면 좋을 것 같다는 생각이 들었습니다.
![]()
우선 XLA (Accelerated Linear Algebra)는 Tensorflow의 서브 프로젝트로 그래프 연산의 최적화 / 바이너리 사이즈의 최소화 등을 목적으로 하는 컴파일러입니다.
결과를 먼저 말씀드리자면, XLA를 활용하는 것을 통해 그래프 연산 과정에 필요한 임시 버퍼도 덜 사용할 수 있고, 그래프 연산 속도도 단축시킬 수 있습니다. (구글 측 자료에 의하면 Nvidia GPU를 사용할 때 50%까지도 성능 향상이 있었다고 합니다.)
예를 들어 아래와 같은 그래프가 있다고 했을때…
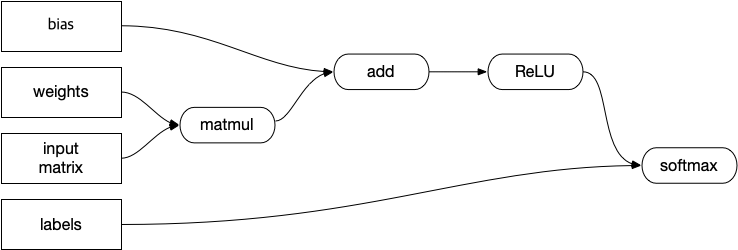
각 연산마다 룹을 돌리는 것이 아니라, 아래와 같은 형식으로 연산을 fuse해서 처리하게 될 경우, 임시 데이터 저장도 줄어들고, 룹도 하나의 룹으로 묶어서 처리가 가능하기 때문에 연산 속도나 임시 버퍼 사용량(및 read/write bandwidth), 캐쉬 효율 측면에서 여러가지 이점을 얻을 수 있습니다.
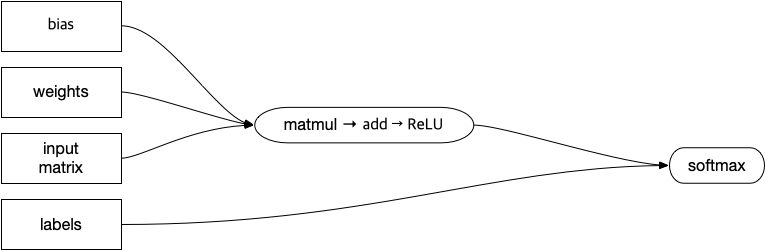
XLA에 있는 그래프 최적화기가 하는 일이 위와 같은 것들이며, XLA에서 하는 일을 간단히 도식화 하면 아래와 같습니다.

XLA도 일종의 컴파일러이기 때문에 일반적인 컴파일러 들이 동작하는 것처럼 FrontEnd (Parser) / MiddleEnd (High-level Optimizer) / BackEnd (Target Code Generator)의 구조를 가지고 있으며, 주어진 타겟 플랫폼에 맞춰 그래프를 최적화 한 후 실행가능한 형태의 무언가를 생성하는 역할을 수행합니다.
BackEnd에서는 LLVM을 사용하고 있으며, LLVM과 마찬가지로 JiT compilation과 AoT compilation 모두를 지원하는게 특징입니다. 두가지 중 어떤 방식을 사용하느냐에 따라 실제 사용 시나리오가 달라지게 되며,
AoT compilation을 사용하는 경우 아래와 같이 컴파일의 결과로 object file 및 이를 사용하기 위한 helper class에 대한 header file이 생성됩니다.
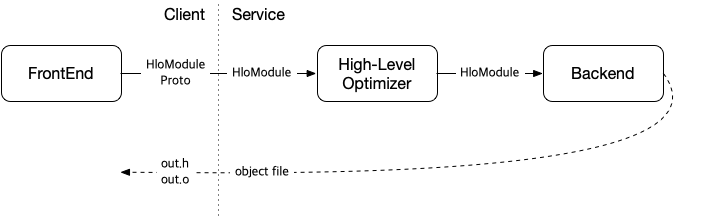
컴파일된 그래프는 아래와 같은 형태의 코드와 링크를 시켜 바이너리로 만든 후 실행할 수 있습니다. (참고: Using AOT compilation)
|
1 2 3 4 5 6 7 8 9 10 |
BlahGraph graph; // Set up args and run the computation. const float args[12] = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12}; std::copy(args + 0, args + 6, graph.arg0_data()); std::copy(args + 6, args + 12, graph.arg1_data()); graph.Run(); std::cout << graph.result0(0, 0) << std::endl; |
실행 바이너리를 만들기 위해 XLA 라이브러리나 Tensorflow 라이브러리 등을 포함할 필요가 없기 때문에 최종 타겟 바이너리 사이즈를 굉장히 작게 만들 수 있으나 기본 CPU backend의 경우 convolution, matmul 등의 연산에 대해 XLA runtime function을 호출하는 코드를 생성하도록 되어 있기 때문에 일부 XLA runtime function들과 링크되어야 할 수도 있습니다.
JiT compilation을 사용하는 경우는 compile의 결과로 XlaExecutable 데이터가 생성되며, StreamExecutor를 통해 input parameter를 feeding하고 그래프를 실행시킬 수 있는 형태입니다.
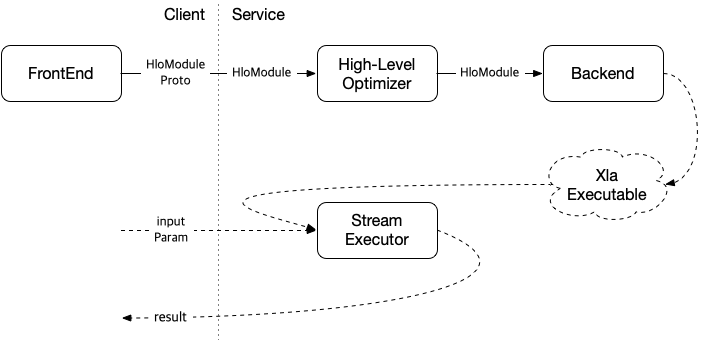
JitCompilation을 사용하는 경우 런타임에 그래프를 입력으로 받아 실행할 수 있다는 장점이 있으나 애플리케이션이 XLA 런타임을 포함해야하기 때문에 eigen, protobuf, LLVM 등등 의존성들이 줄줄이 엮인다는 단점이 있습니다. (타겟 플랫폼에 해당 라이브러리들을 줄줄이 포팅해야할 수도 있습니다.)
애플리케이션을 배포하기 전 단계에 타겟 플랫폼이나 네트워크 형태에 대해 미리 알고 있는 경우에는 AoT compilation을 활용하는 방안을 고려해볼 수 있으며, 애플리케이션은 네트워크를 모르는 상태로 배포되어야 하는 환경이라면 JiT compilation을 사용해야합니다.
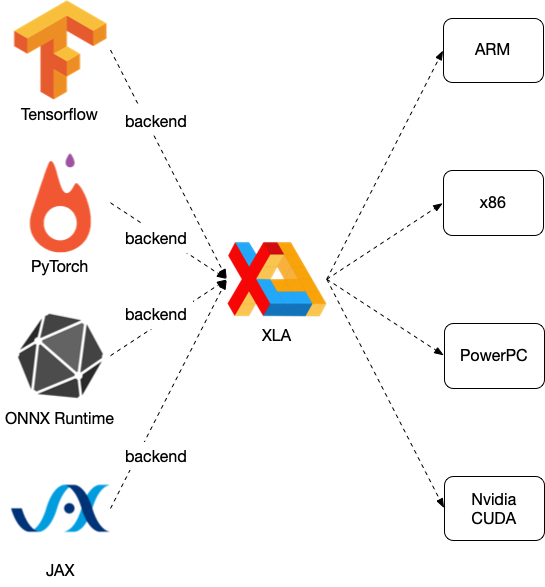
Tensorflow 외에도 다양한 머신러닝 프레임웍의 백엔드로 XLA를 활용할 수 있으며, PyTorch를 위해선 PyTorch XLA, ONNX (Open Neural Network Exchange )를 위해선 onnx xla 프로젝트가 개발되고 있습니다..
Service / Client 구조나 기타 여러가지 재밌는 부분들이 많이 남아있지만 소개글이니 우선은 이 정도로 시작해볼까 합니다.
관심 있으신 분들 있으면 이어서 다른 내용들도 정리를 해보도록 하겠습니다. 😀
추가: 얼마전 ML Compiler 스터디에서 관련 내용을 발표한 자료를 하나 진행했으니 관심있으신 분들은 참고하셔도 좋을 것 같군요.
Similar Posts:
- 머신러닝용 데스크탑 업그레이드 후기…
- msn custom imoticon 백업…
- YUVplayer for MS Windows
- 레트로 게임 환경 구축 완료! – 슈퍼패미콤 편!
- 마우스 드래그, 마우스 오른쪽 버튼을 막아둔 것 풀어버리기