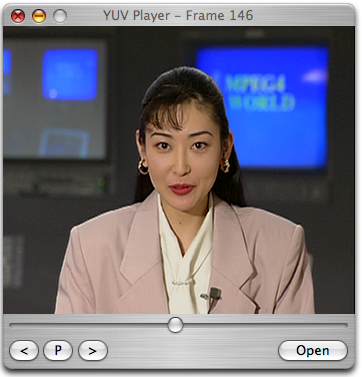
지난 이틀간 작업한 내 YUVPlayer for windows~! MFC + OpenGL 기반으로 작성되었고, 정말 아무 문제 없이 사용할 수 있을만큼 완성도 높게 작업해보기는 처음이 아닐까 싶다. (CUI 기반으로는 공개를 하고 있지는 않았지만 혼자 유용하게 쓰는게 몇 가지 있는데… GUI 기반으로는 정말 처음인 것 같다.)
단축키를 통해 모든 액션을 취할 수 있고, 드래그앤 드롭을 통한 파일 오픈 또한 가능하다. 게다가 _lseeki64 같이 64bit offset 을 사용하는 시스템 콜을 사용하고 있기 때문에 2GB 를 넘어가는 파일들도 문제 없이 플레이가 가능하다. (31GB 짜리 파일도 문제 없이 플레이가 가능한 것을 확인했음.)
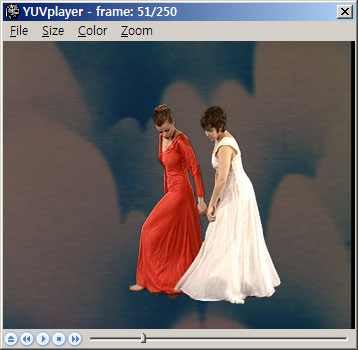
위 스크린 샷은 기본적인 플레이 화면! CBitmapButton 을 통해 이쁜 플레이어 버튼을 만들었고, 여러가지 편법을 통해 –;; 사이즈가 조절되더라도 저 레이아웃이 그대로 유지되도록 만들었다.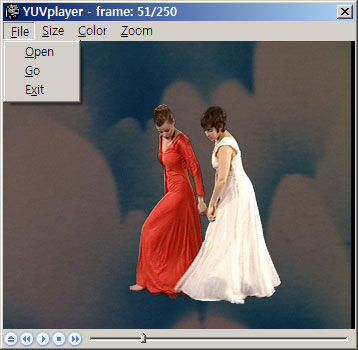
File 메뉴에서는 YUV file 을 열거나 원하는 프레임으로 가는 등의 동작이 가능하다.
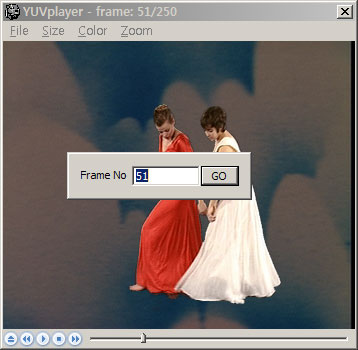
File 메뉴에 있는 Go 버튼을 누르거나 단축키 ‘g’ 를 누르게 되면 위와 같은 창이 뜨게 되는데… frame no 필드에는 기본적으로 현재 플레이되고 있는 프레임 번호가 입력되어 있도록 만들었고, 저기에 원하는 프레임 번호를 입력하게 되면 바로 점프가 가능하다.
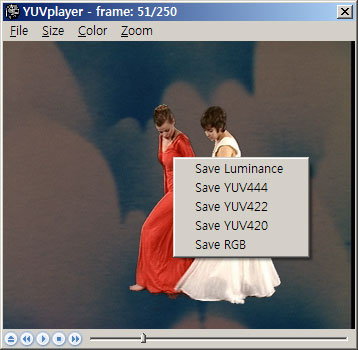
이건 마우스 오른쪽 버튼을 누르면 나오게 되는 컨텍스트 메뉴! 현재 보고 있는 프레임을 파일로 저장할 수 있는 메뉴들을 제공하고 있다. Luminance 성분은 raw 포멧, YUV* 은 YUV 포멧, RGB 는 32bit BMP 포멧으로 저장된다.
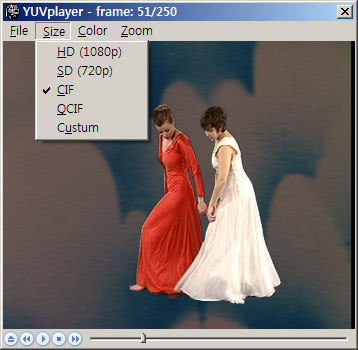
yuv file 은 header 가 없이 데이타만 주루룩 들어가 있는 형태이기 때문에 size 를 알 수가 없으므로 직접 사이즈를 지정해줘야 하는데, 기본 사이즈는 내가 제일 많이 사용하게 될 듯한 CIF (352×288) 사이즈로 지정해두었고, s(SD: 720×480), h(HD: 1920×1080), c(CIF: 352×288), q(QCIF: 176×144), u(Custum) 등의 단축키를 통해 다른 사이즈로도 쉽게 변경할 수 있도록 만들었다.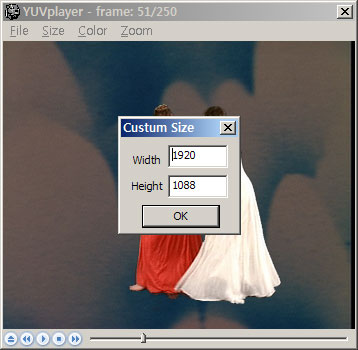
위에 나열해놓은 기본 사이즈가 아니더라도 Custum Size 를 입력할 수 있는 메뉴 또한 준비되어 있다.
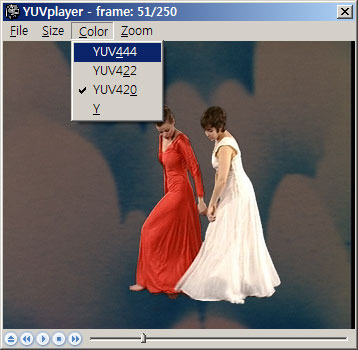
color format 또한 yuv444, yuv422, yuv420, y(luminance only) 등의 포멧을 지원한다.
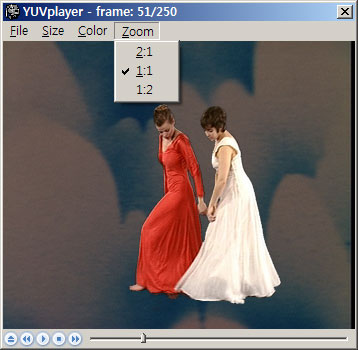
2배 확대, 1/2 축소 등의 기능까지도 제공 -_-v
학부 시절 ‘게임 프로그래밍’ 과목 수강 이후 오랫만에 MFC + openGL 프로그래밍이다보니 가끔 헤매기도 했지만, 잘 설계된 openGL 덕에 기능을 추가하는 것이 쉽게 쉽게 이루어지지 않았나 싶다.
툴도 Visual Studio 2005 로 갈아탔는데, 확실히 여러 면으로 IDE 가 진보했음을 느낄 수 있었다. 다만 Visual Stuido 2005 이거이거 꽤 무거운거 같다. Class Wizard 가 없어졌기 때문에 조금 혼란스럽기도 하지만 뭐 Code Definition Window 등 새로 추가된 기능들은 이런 점을 보완해주고도 남는 듯…
MFC 는 (지금도 잘 모르지만) 거의 초보였는데 요번 프로그램을 통해 좀 자신감이 붙는 것 같다. 원하는 기능을 구현하기 위해 어떤 검색어를 넣으면 될 지에 대한 노하우도 좀 생기는 것 같고, 하여튼 지난 이틀간 이 프로그램을 만들면서 참 재밌었던 것 같다.
이제 남은건 히스토그램을 그려주는 기능 뿐인가!!
다운로드:
Change Log:
2007년 7월 15일
- uyuv 포멧 지원 추가
- 소스 공개
2008년 8월 2일
- ::GetDC(hWnd) 후 ::ReleaseDC(hWnd,dc) 를 호출 하지 않아서 생기는 메모리 릭 제거
- gdTexImage2D 를 반복 호출해서 생기게 되는 메모리 릭 제거
p.s) Visual Studio 에서 만든 프로젝트는 버젼 관리 시스템등에 어떻게 넣어야할지 모르겠다. 하여튼 코드를 조금 더 정리하고, sourceforge 등에 오픈소스 프로젝트로 올려볼 생각!!