저번 주에 개인적으로 de-interlacing 관련된 발표를 준비하느라 논문에 있는 de-interlacing 기법들을 구현해서 실험을 했었는데, 맥에서 돌아가는 yuv player 를 못찾는 바람에 결과는 윈도우로 옮겨서 확인해야하는 불편이 있었다.
랩에 이미 충분히 쓸만한 yuvplayer 가 있기는 하지만 윈도우 전용이고, 내가 예전 신입생 과제를 하면서 만들었던 플레이어 역시 윈도우용;; 뭐 하튼 플레이어를 구현하는데 필요한 기반 테크닉은 다 갖추고 있었기 때문에 MFC + OpenGL 로 구현해봤던 것을 똑같이 Cocoa+OpenGL 로 구현해봤다.
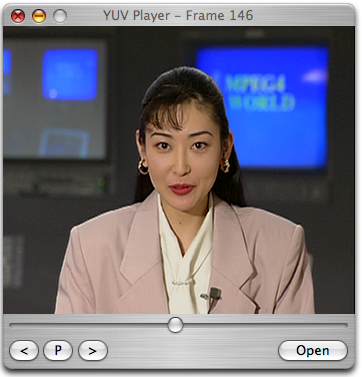
메뉴를 이용해서 size 와 color format, frame rate 등을 준비할 수 있도록 만들었는데, size 와 frame rate 를 사용자가 직접 입력하는 것은 귀찮은 관계로 나중에 -_-;;
뭐 하튼 Zoom 하고 Drag And Drop 과 관련된 코드만 추가하고 나면 내가 구현하고 싶었던 모든 기능이 다 들어가는 거 같다. (Zoom 이야 glPixelZoom 을 사용하면 한방에 오케이니 흐흣)
XCode + Interface Builder 를 이용한 첫 결과물인데, 굉장히 오래전에 이미 나와있던 프로그래밍 인터페이스인데도 불구하고 굉장히 편리하게 프로그래밍이 가능해서 감탄을 해버렸다. 물론 MS 진영도 Visual Studio 2005 로 오면서 편리한 기능들이 꽤 많이 추가되긴 했지만, GUI Application 을 만들기 위한 IDE 로는 XCode + 인터페이스 빌더 쪽이 한 수 위인 듯…
MFC 나 Cocoa 나 진입 장벽이 꽤 높지만… 기본적인 테크닉을 익히고 나면 굉장히 강력하게 사용이 가능한 것 같다. 그리고 C 에 능숙하다면 다른 언어를 접하는 데도 그리 큰 어려움을 느끼지 않는 것 같다. 학부 시절 C++, Java 등에 눈길을 뺐기지 않고 주력 언어로 C 를 선택했던 게 탁월한 선택이었던 듯…
p.s) 코드를 좀 정리하고 sourceforge 등에 자리를 틀어볼까 싶네요. 🙂
처음 짜본 wavelet transform…
화상처리기초 수업 과제 때문에 처음으로 wavelet transform 을 구현해보았습니다. 아래 이미지는 wavelet 으로 변환된 512×512 사이즈의 lena
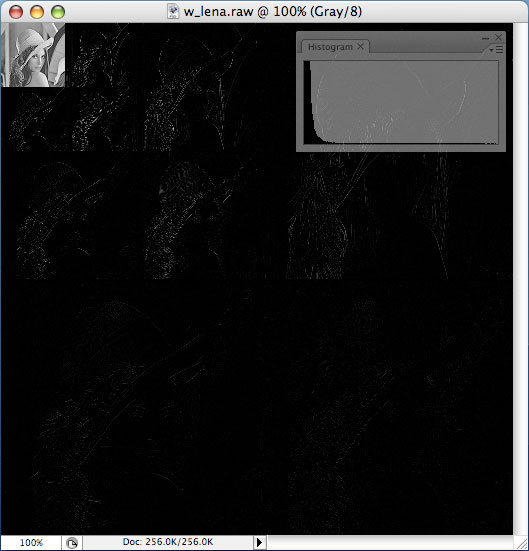
histogram 을 보면, 값들이 낮은 값들로 집중되어 있는걸 확인할 수 있습니다. 역시 이미지 압축을 위해 사용할만 하네요. 😉
matrix multiply with mmx #2

대강 생각을 해보니 정말 mmx 를 이용해서 빠르게 연산을 하려면 위와 같이 하는게 가장 빠르겠군요. 다만 레지스터를 많이 쓰고 완전히 asm 코딩을 해야한다는 게 조금 귀찮겠군요. 😉
위의 다이아그램에 있는 과정을 통해 4×4 matrix * 4×4 matrix 의 한 row 씩을 계산해낼 수 있습니다. 대강 계산했을 때 3배 이상의 속도 향상이 있을거라고 예상되던데 과연~
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 |
#include <stdio .h> // A matrix short s1[16] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, }; // Transpose(B matrix) short s2[16] = { 17, 21, 25, 29, 18, 22, 26, 30, 19, 23, 27, 31, 20, 24, 28, 32 }; // Destination matrix short d[16]; int j, i; int main( int argc, char** argv ){ __asm__("movq (s1), %mm0" ); __asm__("movq %mm0, %mm1" ); __asm__("movq %mm0, %mm2" ); __asm__("punpckhdq %mm2, %mm0" ); __asm__("punpckldq %mm2, %mm1" ); __asm__("movq %mm0, %mm6"); __asm__("movq %mm1, %mm7"); __asm__("movq (s2), %mm2" ); __asm__("mov $1, %eax" ); __asm__("movq s2(,%eax,8), %mm4"); __asm__("movq %mm2, %mm3" ); __asm__("punpckhdq %mm4, %mm2"); __asm__("punpckldq %mm4, %mm3"); __asm__("pmaddwd %mm2, %mm0"); __asm__("pmaddwd %mm3, %mm1"); __asm__("paddw %mm1, %mm0"); __asm__("movq %mm6, %mm1"); __asm__("movq %mm7, %mm2"); __asm__("mov $2, %eax" ); __asm__("movq s2(,%eax,8), %mm3" ); __asm__("mov $3, %eax" ); __asm__("movq s2(,%eax,8), %mm5"); __asm__("movq %mm3, %mm4" ); __asm__("punpckhdq %mm5, %mm3"); __asm__("punpckldq %mm5, %mm4"); __asm__("pmaddwd %mm3, %mm1"); __asm__("pmaddwd %mm4, %mm2"); __asm__("paddw %mm2, %mm1"); __asm__("packssdw %mm1, %mm0"); __asm__("movq %mm0, (d)"); for( j = 0 ; j < 4 ; j++ ){ for( i = 0 ; i < 4 ; i++ ){ fprintf( stderr, "\t%3d", d[j*4+i] ); } fprintf( stderr, "\n" ); } return 0; } |
코드로 옮기니 위와 같군요. 중간에 실수로 바이트오더를 헷갈려서 연산 결과가 뒤집혔었습니다. 정상적인 결과는 250 260 270 280 이 나와야 하는데 280 270 260 250 이 나와버리더군요. 아아 이거 다시 하고 싶은 작업이 아니네요;
흐흣 그래도 오랫만에 어셈블리 관련된 것들을 생각하고 있는데, 이것도 가끔 하니까 재밌네요. 근데 길어지면 할만하지 않다는거 -_-!
p.s) 전체 연산 코드를 보고 싶으시면 http://mytears.org/resources/mysrc/c/mmx.c 를 보시길 😉
matrix multiply with mmx #1
몇 일 전에 썼던 글에서 테스트를 해본 내용을 바탕으로 4×4 matrix multiply 연산을 mmx 를 이용해서 구현해봤습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
#include <stdio .h> // A matrix short s1[16] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, }; // Transpose(B matrix) short s2[16] = { 17, 21, 25, 29, 18, 22, 26, 30, 19, 23, 27, 31, 20, 24, 28, 32 }; // Destination matrix short d[16]; short t[4]; int i, j; long start, end; int main( int argc, char** argv ){ int k; for( j = 0 ; j < 4 ; j++ ){ for( i = 0 ; i < 4 ; i++ ){ d[j*4+i] = 0; for( k = 0 ; k < 4 ; k++ ){ d[j*4+i] += s1[j*4+k] * s2[i*4+k]; } } } fprintf( stderr, "c version\n\n" ); for( j = 0 ; j < 4 ; j++ ){ for( i = 0 ; i < 4 ; i++ ){ fprintf( stderr, "\t%3d", d[j*4+i] ); } fprintf( stderr, "\n" ); } return 0; } |
위와 같은 c version 의 코드를 작성한 후 아래와 같은 asm version 으로 컨버팅을 해봤는데, 100000 번 반복해서 연산을 하도록 해본 결과 mmx 버젼이 c 버젼보다 3배 정도 빠르게 연산을 하는 것을 확인할 수 있었습니다. (-O0 옵션과 함께 컴파일 했을 경우)
하지만 -O3 옵션과 함께 컴파일하게 되면 asm 버젼은 무한룹에 빠진 듯한 모습을 보여줬고, c 버젼의 수행속도가 -O0 로 컴파일한 asm 버젼보다 빠른 현상이 발생했습니다. 이유는 알 수 없음 -_-;
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
#include <stdio.h> #include <asm /mmx.h> // A matrix short s1[16] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, }; // Transpose(B matrix) short s2[16] = { 17, 21, 25, 29, 18, 22, 26, 30, 19, 23, 27, 31, 20, 24, 28, 32 }; // Destination matrix short d[16]; short t[4]; int i, j; int main( int argc, char** argv ){ int loop; for( loop = 0 ; loop < 10000; loop++ ){ for( j = 0 ; j < 4 ; j++ ){ for( i = 0 ; i < 4 ; i++ ){ __asm__("mov j, %eax"); __asm__("movq s1(,%eax,8), %mm0" ); __asm__("mov i, %eax"); __asm__("movq s2(,%eax,8), %mm1" ); __asm__("pmullw %mm1, %mm0"); __asm__("movq %mm0, (t)" ); d[j*4+i] = t[0] + t[1] + t[2] + t[3]; } } } for( j = 0 ; j < 4 ; j++ ){ for( i = 0 ; i < 4 ; i++ ){ fprintf( stderr, "\t%3d", d[j*4+i] ); } fprintf( stderr, "\n" ); } return 0; } |
8×8 matrix 는 뭔가 좀 더 생각해야할 것 같으니 나중에 정말 필요한 일 있을 때 구현을 해봐야겠습니다. -_-;
inline asm 작업을 하면서 eax 레지스터 값을 백업하지 않고 저렇게 사용해도 되는지는 잘 모르겠지만 –;; 하여튼 저 코드에 한해서는 별 문제 없으니 패스~ 꺄홋!!
mmx
요새 matrix 연산을 이용한 프로그램 조각 몇 가지를 짜보고 있는데, mmx 같은 SIMD instruction 을 사용하면 matrix 연산의 속도를 확 올릴 수 있지 않을까 싶은 생각이 들길래 inline asm 을 이용해서 간단한 mmx 코드를 만들어보았습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
#include <stdio.h> short s1[4] = { 1, 2, 3, 4 }; short s2[4] = { 5, 6, 7, 8 }; short d[4]; int main( int argc, char** argv ){ d[0] = s1[0] * s2[0]; d[1] = s1[1] * s2[1]; d[2] = s1[2] * s2[2]; d[3] = s1[3] * s2[3]; fprintf( stderr, "c: %d %d %d %d\n", d[0], d[1], d[2], d[3] ); d[0] = d[1] = d[2] = d[3] = 0; asm("movq (s1), %mm0"); asm("movq (s2), %mm1"); asm("pmullw %mm1, %mm0"); asm("movq %mm0, (d)"); fprintf( stderr, "asm: %d %d %d %d\n", d[0], d[1], d[2], d[3] ); return 0; } |
위와 같은 코드를 작성하고, gcc mmx.c 를 통해 컴파일해서 돌려보니 간단히 성공 -_-v
c 코드를 사용할 경우 s1[0] load, s2[0] load, multiply, save to d[0] 와 같은 인스트럭션을 네 번 반복해서 실행하는 반면 mmx 를 사용할 경우 movq 를 통해 연속된 WORD 네 개를 mmx register 로 복사하고, pmullw 를 이용 4 개의 값을 한 인스트럭션에 연산을 하는 것을 통해 속도를 확 끌어올릴 수 있는거죠. 😉
다만 헷갈리는게 인텔의 메뉴얼에 나와있는 인자 순서와, AT&T 방식이 달라서 좀 헷갈리는군요.
- Intel: movq mm0, [s1]
- AT&T: movq (s1), %mm0
Intel 메뉴얼에서 설명하는 바에 의하면 첫번째 operland 가 destination 이 되고, 두번째 operland 가 destination 이 되는 반면 AT&T 방식에서는 거꾸로 첫번째 operland 가 src, 두번째 operland 가 dst 가 됩니다.
또한 주소값을 넘겨줄 때 intel 방식은 [] 로 감싸주면 되지만, AT&T 에서는 () 로 감싸줘야하고, 레지스터 이름 앞에 %를 붙여줘야 하는 규칙도 있어서 뭔가 대빵 귀찮네요. -_-;
참고로 gcc 에서 -masm=intel 옵션을 사용하면 intel 방식으로 어셈블리 명령어를 작성하는 것도 가능합니다.
p.s) movq 는 4개의 WORD 를 mmx register 로 복사하는 명령인데 –;; mm0 ~ mm7 식으로 64bit register name 을 써줘야 하는데 xmm0~xmm7 같은 sse 용 register 이름을 쓰는 바람에 잘못된 인스트럭션 사용이라고 계속 에러가나서 한참 헤맸네요;
avr gadget
몇 일전에 만들었던 avr 로 만든 장난감의 회로도와 소스코드를 공개합니다. 🙂
회로도:
http://mytears.org/resources/avr/gadget/avr-gadget-circuit.png
소스코드:
http://mytears.org/resources/avr/gadget/avr-gadget.c
결과물:
http://mytears.org/tmp/dir/?path=./avr&N
회로에서 Vcc 라고 되어있는 부분에 2.7V ~ 5.5V 사이로 연결을 해주면 되며, 회로에는 나와있지 않지만 10번 핀은 Ground 에 연결해줘야만 합니다. 또한 Vcc 에 3V 를 연결하게 될 경우 L.E.D 에 저항은 연결할 필요가 없습니다. (330옴은 5V 기준)
프로그램을 간단하게 설명하자면 8bit timer 를 사용했고, timer 에 overflow 가 발생할 때 (0xFF 에서 0x00 으로 넘어가게 되면) 생기는 ovf 인터럽트를 이용하고 있습니다.
처음엔 at90s2313 을 사용했었는데 불행히도 가지고 있는 at90s2313 중 하나는 다리가 부러져서 사망해버렸고, 나머지 하나는 뻘짓하다가 태워먹어버린고로 현재 소스코드는 attiny2313 용으로 작성되어 있습니다. (두 칩은 핀 배열등 대부분이 비슷하지만 ovf 인터럽트와 timer 관련 레지스터 이름이 살짝 다릅니다.)
인터럽트 테스트 코드:
http://mytears.org/resources/avr/interrupt-test/int-test.c
p.s) 결국 하나 남은 attiny2313 마저 장렬하게 전사… 프로젝트 검사를 아직 안받은고로 추가 주문 해야했다.
오늘의 교훈: 겁 없이 7805 를 믿고 15v 아답타에 연결하지 말자 -_-;;
AVR-ISP
오랫만에 AVR 을 가지고 노니까 재밌길래 범용으로 쓸 수 있을만한 AVR-ISP 를 만들었습니다. 40pin ZIF 소켓을 사용해서 쉽게 칩을 꼈다뺐다할 수 있도록 만들었고, pin header 를 이용해서 Vcc, GND, RESET, SCK, MISO, MOSI, XTAL1, XTAL2 등을 칩에 맞게 연결할 수 있도록 만들어놓았습니다.


이 칩 저 칩을 구울라면 점퍼 세팅을 다시 해줘야 하지만, 뭐 그래도 빵판에 꼽아놓고 구울 때에 비하면 훨씬 편해진 것 같습니다. 하지만 마이크로마우스 같은 계속적인 디버깅 / 개선을 해야하는 것을 만든다면 아예 보드에 ISP 와 연결할 수 있는 인터페이스를 갖춰놓는 것이 훨씬 효율적일 거 같네요. 칩을 뺐다꼈다하는것도 은근히 귀찮아요. -_-;
부품 리스트: 40 pin ZIF socket, 40pin pin header, box connector, 4Mhz crystal, 10uF capacitor, 100nF capacitor, 30pf capacitor * 2, diode bridge, LM7805, 330옴 array register, red L.E.D (전원 확인용), green L.E.D (다운로딩 상태 확인용)
p.s) 제가 처음 접했던 8051 계열의 경우도 AT89S51 등의 ISP 가 지원되는 칩이 있었네요.
AVR
실험(4) 과목 때문에 스트레스가 여간이 아닙니다. 중간고사 평균이 8점이었고, 중간 + 기말 + Report 점수를 합산한게 70점을 넘지 않으면 F 를 주시겠다는군요. 문제는 이 과목이 전공 필수이고, 전 요번학기가 마지막이어야만 한다는 거죠.
하여튼 그런 이유로 추가 점수를 받기 위해 오랫만에 AVR 을 만져야 했습니다. AVR 은 ATMEL 에서 만든 MCU 로 ISP 인터페이스를 갖추고 있어서 복잡한 롬라이터를 만들지 않고도 간단하게 프로그램을 구울 수 있습니다.

실험(4) 시간에 atmega128 과 관련 보드 / ISP 가 지급이 되었지만, 뗌질을 하다가 칩을 태워먹은건지 아님 어딘가 뗌질이 잘못된건지 하여튼 작동하지를 않더군요. 어쩔 수 없이 예전에 사두었던 AT90S2313 을 이용하기로 마음을 먹고 위의 사진처럼 빵판에 회로를 구성했습니다. 보기엔 좀 그렇지만 하여튼 작동은 잘 하는군요. 후훗

결국 두 시간동안 열혈 뗌질을 한 끝에 위와 같은 최종 결과물을 만들어냈습니다. I/O 가 모잘라서 500원 투입 버튼은 만들지 않았지만, 그걸 제외하면 구현해야 하는 스펙은 모조리 구현해놓았습니다.
모처럼 오랫만에 mcu 를 가지고 놀았더니 재밌네요. 필받은 김에 아래와 같은걸 추가로 뗌질해봤습니다.

예전에 홍익대학교 전자전기공학부 학회인 유레카에서 유행했던 겁니다 😉 축제 때 팔기도 했던걸로 알고 있는데… 뭐 하여튼 L.E.D 에 저항연결하기도 귀찮고, 전원을 따로 입력받기도 귀찮고 해서 3V 로 동작하게 만들어버렸습니다.
아래 사진은 밤에 불을 다 꺼놓고 노출을 1s 로 해놓은 뒤 위 회로를 살짝 흔들어준 모습입니다. 메시지를 길게 넣을 수도 있지만 그 노가다가 귀찮아서 -_-;

위 회로를 업그레이드 해서 ^_^, -_-, T.T, 하트 등을 그릴 수 있도록 업데이트 했습니다. 결과물을 보시려면 아래 url 로 😉
http://mytears.org/tmp/dir/?path=./avr&N
p.s) 참고로 AVR 을 굽기 위해선 MISO / MOSI / SCK / RESET (ISP 에서 입력을 받습니다.), VCC, GND 그리고 XTAL1, XTAL2 (크리스탈) 정도만 연결해주면 됩니다. 예전에 VCC, GND 등은 패러랠 포트에서 들어오는 건 줄 알고 삽질한 기억이 나서;;;
맘에 드는 문구…
공기 역학의 법칙에 따라 나비를 관찰한다면, 그것은 날 수 없어야 한다. 그러나 나비는 그것을 모른다. 그러므로 날 수 있는 것이다.
함부로 한계 짓지 말자! 아자!!!
새 백업 스크립트…
예전 스크립트에서는 그냥 특정 사용자에 한해서 백업을 하도록 하고 있었습니다. 하지만 백업의 중요성을 절실히 느끼게 되서, 요번엔 사용자의 계정 사용량을 체크해서 1기가 미만으로 사용을 하고 있다면 자동으로 백업을 하도록 만들었습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
#!/bin/sh TMPWATCH="/usr/sbin/tmpwatch" cd /home/member for member in *;do if [[ -d "${member}" ]];then # get usage usage=`du -s "${member}"|awk '{ print $1 }'` # remain only one item if [[ -d "/backup/home/${member}" ]];then lastone=`ls -t "/backup/home/${member}" | head -n 1` if [[ -f "/backup/home/${member}/${lastone}" ]];then touch -m "/backup/home/${member}/${lastone}" fi ${TMPWATCH} --mtime 1 "/backup/home/${member}" else mkdir -p "/backup/home/${member}" fi # if usage is less than 1.4GB if [ ${usage} -le 1400000 ]; then tar cfzp "/backup/home/${member}/${member}-`date +%y%m%d`.tar.gz" "${member}" fi fi done |
또한 ls 와 head, tmpwatch 를 이용해서 백업본이 최신 2 개만이 유지되도록 만들어놓았습니다. 만약 타르볼로 묶는데 1시간 이상 걸리는 용량을 아카이빙 하면 문제가 될 수 있습니다. –;