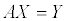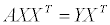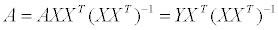kldp 를 눈팅하다가 오늘 재밌는 문서를 읽게 되었습니다. 2001년도에 AMD 에서 나온 문서였는데, 그 내용이 상당히 흥미로워서 몇 가지 내용을 옮겨볼까 합니다.
메모리에서 연속된 값들을 다른 곳으로 복사하기 위해 사용할 수 있는 가장 간단한 어셈블리 코드는 다음과 같습니다.
|
1 2 3 4 5 |
mov esi, [src] // source array mov edi, [dst] // destination array mov ecx, [len] // number of QWORDS (8 bytes) shl ecx, 3 // convert to byte count rep movsb |
rep movsb 명령은 repeat move single byte (바이트 단위로 값들을 반복해서 옮긴다.)라는 의미를 가집니다. esi 가 가리키는 곳에 있는 값을 edi 로 ecx 에 있는 개수 만큼 복사하게 됩니다. 이렇게 할 경우 일초에 약 620MB 를 복사할 수 있다고 하네요.
이 코드를 byte 단위가 아니라 4 byte 단위로 반복해서 복사를 하도록 하면 어떻게 될까요? 우선 코드는 다음과 같이 변하겠네요.
|
1 2 3 4 5 |
mov esi, [src] // source array mov edi, [dst] // destination array mov ecx, [len] // number of QWORDS (8 bytes) shl ecx, 1 // convert to DWORD count rep movsd |
shl 인스트럭션은 두개의 오퍼랜드를 가지며 (shl operand1 operand2) operand1 에 있는 값을 operand2 에 있는 값만큼 왼쪽으로 shift 를 시키게 됩니다. movsd 는 mov single dword[1] 라고 보시면 됩니다.
결과적으로 이렇게 코드를 수정함으로 인해 1초에 640MB 를 복사할 수 있게 됩니다. 3% 정도 성능 향상이 생기네요.
그런데 최근에 나온 프로세서들에서는 rep 같은 복잡한 인스트럭션을 내부적으로 RISC 명령으로 바꿔서 실행하다 보니, 그리 효율적이지 못하답니다. 그러므로 rep 를 사용하지 말고 반복문을 사용해보도록 합시다.
|
1 2 3 4 5 6 7 8 9 10 11 |
mov esi, [src] // source array mov edi, [dst] // destination array mov ecx, [len] // number of QWORDS (8 bytes) shl ecx, 1 // convert to DWORD count copyloop: mov eax, dword ptr [esi] mov dword ptr [edi], eax add esi, 4 add edi, 4 dec ecx jnz copyloop |
코드가 뭔가 좀 길어졌죠? 위 코드를 c로 표현하면 아래와 같습니다.
|
1 2 3 4 5 |
int* src = esi; int* dst = edi; int i; for( i = len ; i != 0 ; i-- ){ dst++ = src++; |
c로 표현하니 어디서 많이 쓰던 코드죠? 쨌든! 이렇게 하니 1초에 650MB 를 복사할수 있었고 결과적으로 1.5% 정도 성능이 향상되었답니다.
그럼 여기다가 Loop 코드를 최적화 하는 기법인 Loop Unrolling 을 적용해봅시다. [2]
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
mov esi, [src] // source array mov edi, [dst] // destination array mov ecx, [len] // number of QWORDS (8 bytes) shr ecx, 1 // convert to 16-byte size count // (assumes len / 16 is an integer) copyloop: mov eax, dword ptr [esi] mov dword ptr [edi], eax mov ebx, dword ptr [esi+4] mov dword ptr [edi+4], ebx mov eax, dword ptr [esi+8] mov dword ptr [edi+8], eax mov ebx, dword ptr [esi+12] mov dword ptr [edi+12], ebx add esi, 16 add edi, 16 dec ecx jnz copyloop |
자 룹을 펼쳤더니 1초에 640MB 를 복사하였고, 결과적으로 1.5% 만큼 성능이 떨어졌습니다. 하지만 다행히도 Loop Unrolling 을 적용하고 나니 최적화를 할 여지가 많아졌네요.
캐쉬를 좀 더 잘 활용할 수 있도록 코드 순서를 바꿔봅시다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
mov esi, [src] // source array mov edi, [dst] // destination array mov ecx, [len] // number of QWORDS (8 bytes) shr ecx, 1 // convert to 16-byte size count copyloop: mov eax, dword ptr [esi] mov ebx, dword ptr [esi+4] mov dword ptr [edi], eax mov dword ptr [edi+4], ebx mov eax, dword ptr [esi+8] mov ebx, dword ptr [esi+12] mov dword ptr [edi+8], eax mov dword ptr [edi+12], ebx add esi, 16 add edi, 16 dec ecx jnz copyloop |
이젠 1초에 660MB 를 복사할 수 있게 되었고, 3% 만큼 성능 향상이 일어났습니다.
여기서 끝이 아닙니다. 첨에 movsb 대신 movd 를 사용해서 1byte씩이 아닌 4byte 씩 복사를 하는 방법을 통해 최적화를 진행했었는데요, MMX 를 사용할 경우 movq 등의 인스트럭션을 이용해서 한 번에 8byte 씩을 복사하는게 가능해집니다. 또한 mm0~7 이라는 특수한 레지스터를 활용할 수 있으니 8*8 = 64 즉 한번에 64byte 씩을 복사해봅시다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
mov esi, [src] // source array mov edi, [dst] // destination array mov ecx, [len] // number of QWORDS (8 bytes) lea esi, [esi+ecx*8] // end of source lea edi, [edi+ecx*8] // end of destination neg ecx // use a negative offset copyloop: movq mm0, qword ptr [esi+ecx*8] movq mm1, qword ptr [esi+ecx*8+8] movq mm2, qword ptr [esi+ecx*8+16] movq mm3, qword ptr [esi+ecx*8+24] movq mm4, qword ptr [esi+ecx*8+32] movq mm5, qword ptr [esi+ecx*8+40] movq mm6, qword ptr [esi+ecx*8+48] movq mm7, qword ptr [esi+ecx*8+56] movq qword ptr [edi+ecx*8], mm0 movq qword ptr [edi+ecx*8+8], mm1 movq qword ptr [edi+ecx*8+16], mm2 movq qword ptr [edi+ecx*8+24], mm3 movq qword ptr [edi+ecx*8+32], mm4 movq qword ptr [edi+ecx*8+40], mm5 movq qword ptr [edi+ecx*8+48], mm6 movq qword ptr [edi+ecx*8+56], mm7 add ecx, 8 jnz copyloop emms // empty the MMX state |
MMX 용 레지스터들인 mm0~7 은 FPU stack 의 일부를 활용하게 되므로, 이 레지스터 값을 바꿔주게 될 경우 FPU 와 관련해서 문제를 일으킬 수 있습니다. EMMX 는 이를 방지하기 위해 사용해야 하는 인스트럭션이 되겠습니다. 하여튼 이렇게 바꾸니 1초에 705MB 를 복사할 수 있게 되었고, 7% 만큼 성능이 향상되었습니다.
이젠 movntq 라는 인스트럭션을 통해 cache 를 우회해서 writing 을 진행해봅시다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
mov esi, [src] // source array mov edi, [dst] // destination array mov ecx, [len] // number of QWORDS (8 bytes) lea esi, [esi+ecx*8] lea edi, [edi+ecx*8] neg ecx copyloop: movq mm0, qword ptr [esi+ecx*8] movq mm1, qword ptr [esi+ecx*8+8] movq mm2, qword ptr [esi+ecx*8+16] movq mm3, qword ptr [esi+ecx*8+24] movq mm4, qword ptr [esi+ecx*8+32] movq mm5, qword ptr [esi+ecx*8+40] movq mm6, qword ptr [esi+ecx*8+48] movq mm7, qword ptr [esi+ecx*8+56] movntq qword ptr [edi+ecx*8], mm0 movntq qword ptr [edi+ecx*8+8], mm1 movntq qword ptr [edi+ecx*8+16], mm2 movntq qword ptr [edi+ecx*8+24], mm3 movntq qword ptr [edi+ecx*8+32], mm4 movntq qword ptr [edi+ecx*8+40], mm5 movntq qword ptr [edi+ecx*8+48], mm6 movntq qword ptr [edi+ecx*8+56], mm7 add ecx, 8 jnz copyloop sfence emms |
movntq 를 활용한 다음에는 write buffer 를 비워주기 위해 sfence 를 사용해야 한다는군요. write 부분이 movq 에서 movntq 로 바뀌었고 emms 앞에 sfence 가 들어간 것을 제외하면 코드는 동일합니다. 하지만 성능 향상은 60% 로 굉장하네요. 1초에 1130MB 를 복사할 수 있었다고 합니다.
이젠 prefetch 도 활용해봅시다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
mov esi, [src] // source array mov edi, [dst] // destination array mov ecx, [len] // number of QWORDS (8 bytes) lea esi, [esi+ecx*8] lea edi, [edi+ecx*8] neg ecx copyloop: prefetchnta [esi+ecx*8 + 512] // fetch ahead by 512 bytes movq mm0, qword ptr [esi+ecx*8] movq mm1, qword ptr [esi+ecx*8+8] movq mm2, qword ptr [esi+ecx*8+16] movq mm3, qword ptr [esi+ecx*8+24] movq mm4, qword ptr [esi+ecx*8+32] movq mm5, qword ptr [esi+ecx*8+40] movq mm6, qword ptr [esi+ecx*8+48] movq mm7, qword ptr [esi+ecx*8+56] movntq qword ptr [edi+ecx*8], mm0 movntq qword ptr [edi+ecx*8+8], mm1 movntq qword ptr [edi+ecx*8+16], mm2 movntq qword ptr [edi+ecx*8+24], mm3 movntq qword ptr [edi+ecx*8+32], mm4 movntq qword ptr [edi+ecx*8+40], mm5 movntq qword ptr [edi+ecx*8+48], mm6 movntq qword ptr [edi+ecx*8+56], mm7 add ecx, 8 jnz copyloop sfence emms |
위 코드에는 현재 복사할 차례의 512 바이트를 미리 읽어두라는 의미의 prefetchnta 인스트럭션이 추가되었습니다. 한 번에 복사하는건 64Byte 인데 왜 512Byte 를 읽으라고 했는지 살짝 의문이네요. 제 생각에는 문서를 작성하신 분이 버그를 낸거라고 생각합니다.
하여튼 이젠 1초에 1240MB 를 복사할 수 있게 되었고, 10% 만큼 더 성능 향상이 생겼네요.
지금까지의 방법만으로도 꽤 많은 성능 향상이 있었지만, 한 번에 한 캐쉬 라인[3]만을 활용하고 있습니다. 하지만 실제 CPU 에는 훨씬 많은 캐쉬 라인이 존재하므로 이를 더 잘 활용할 수 있도록 코드를 수정해보겠습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 |
#define CACHEBLOCK 400h // number of QWORDs in a chunk mov esi, [src] // source array mov edi, [dst] // destination array mov ecx, [len] // total number of QWORDS (8 bytes) // (assumes len / CACHEBLOCK = integer) lea esi, [esi+ecx*8] lea edi, [edi+ecx*8] neg ecx mainloop: mov eax, CACHEBLOCK / 16 // note: prefetch loop is unrolled 2X add ecx, CACHEBLOCK // move up to end of block prefetchloop: mov ebx, [esi+ecx*8-64] // read one address in this cache line... mov ebx, [esi+ecx*8-128] // ... and one in the previous line sub ecx, 16 // 16 QWORDS = 2 64-byte cache lines dec eax jnz prefetchloop mov eax, CACHEBLOCK / 8 writeloop: movq mm0, qword ptr [esi+ecx*8] movq mm1, qword ptr [esi+ecx*8+8] movq mm2, qword ptr [esi+ecx*8+16] movq mm3, qword ptr [esi+ecx*8+24] movq mm4, qword ptr [esi+ecx*8+32] movq mm5, qword ptr [esi+ecx*8+40] movq mm6, qword ptr [esi+ecx*8+48] movq mm7, qword ptr [esi+ecx*8+56] movntq qword ptr [edi+ecx*8], mm0 movntq qword ptr [edi+ecx*8+8], mm1 movntq qword ptr [edi+ecx*8+16], mm2 movntq qword ptr [edi+ecx*8+24], mm3 movntq qword ptr [edi+ecx*8+32], mm4 movntq qword ptr [edi+ecx*8+40], mm5 movntq qword ptr [edi+ecx*8+48], mm6 movntq qword ptr [edi+ecx*8+56], mm7 add ecx, 8 dec eax jnz writeloop or ecx, ecx // if( ecx != 0 ) jnz mainloop // goto mainloop sfence |
여기서는 cache 가 1024 개의 cache line 을 가지고 있다고 가정했네요. (16진수인 400h 는 10진수로 바꿀 경어 1024 가 됩니다.) 미리 캐쉬 사이즈만큼 prefetch 명령들을 내려놓은 뒤 값들을 복사하게 될 때 쯤이면 이미 값들이 캐쉬에 올라와있게 되니 딜레이를 줄일 수 있게 되겠습니다.
효과가 있을까 싶지만, 실제 1초에 1976MB 를 복사할 수 있었고, 59% 의 성능향상이 추가로 발생했습니다. 초기 코드에 비하면 300% 의 성능 향상이라네요. 신기하죠. 😉
전 상당히 흥미롭게 읽었었는데, (비슷한 걸 해본 경험도 있고 해서) 재밌었는지 모르겠네요. sfence 나 movqnta, prefetchnta 같은 캐쉬와 관련된 명령들은 정확히 무슨 용도인지 이해하지 못하고 있었는데 이 문서를 통해 이해할 수 있었던 것 같네요. 관심이 있으신 분은 아래 문서를 읽어보시면 되겠습니다. FPU 관련된 최적화도 다루고 있는데, 관심이 없어서 그 부분은 옮기질 않았습니다. 그럼 다들 즐거운 주말 보내시길 😉
[1] x86 호환 아키텍쳐에서는 사이즈를 byte, word, dword, qword, dqword 식으로 표현합니다. 이는 각각 1, 2, 4, 8, 16 바이트를 의미하며, word 가 2바이트이고 나머지의 앞에 붙은 알파벳들은 각각 double(*2), quad(*4), double quad(*8)를 나타내는 것이죠.
[2] Loop Unrolling 은 Loop 을 펼쳐서 파이프라인의 덕을 더 많이 볼 수 있도록 코드를 수정하는 방법입니다. 예를 들어
|
1 2 |
for ( i = 0 ; i < 16 ; i++ ) dst[i] = src[i]; |
위와 같은 코드를
|
1 2 3 4 5 6 |
for ( i = 0 ; i < 16 ; i+=4 ){ dst[i] = src[i]; dst[i+1] = src[i+1]; dst[i+2] = src[i+2]; dst[i+3] = src[i+3]; } |
이렇게 바꿀 경우 branch 로 인한 pipeline hazard 도 줄일 수 있고, add instruction 도 1/4 만큼만 사용하게 됨으로 인해 성능이 향상될 여지가 많습니다.
[3] 메모리에 어떤 값을 읽어들일 때 CPU 에서는 바이트 단위로 값을 읽지 않고, block 단위로 값들을 cache 에 복사하는데, 이 block 의 크기를 cache line 이라고 표현합니다. 펜티엄 계열의 경우 대부분 64byte 입니다.